
The Hidden Performance Cost of NodeJS and GraphQL
NodeJS and GraphQL are popular technologies for building web applications, but in my experience, they come with certain scaling and performance tradeoffs to be aware of.
tl;dr: GraphQL's modular structure generally leads to code that instantiates excessive promises, which degrades request performance. Benchmarks show a 2-3x latency increase.
Background
NodeJS is known for its non-blocking I/O operations, thanks to its design of the event loop. The event loop is a single dispatcher thread that enables concurrent I/O operations without forcing developers to reason about managing parallelism.
All synchronous work in NodeJS happens on the event loop thread (other than a few isolated multithreaded features like worker_threads). When the event loop is managed well, and I/O is a true bottleneck, NodeJS can be a very efficient/scalable technology.
On the other hand, if a request does a lot of processing on the event loop, it will block other requests on that container. NodeJS applications are particularly susceptible to sporadic performance issues due to noisy neighbors - other heavy request handlers - that overly consume the event loop. Additionally, GraphQL's resolver structure can result in more promise overhead compared to REST endpoints, which may cause suboptimal user-perceived latency if not managed carefully.
GraphQL and the Event Loop
GraphQL enables a modular design for APIs. For example, we can define a type in our schema, and define one resolver for that type, regardless of where that type appears in the graph.
// schema.
// we only have to define one type resolver for User
type User {
name: String!
accountId: String!
friends: [User!]!
}
type Query {
user: [User!]!
}
// query.
// we can pick the fields we need.
query q {
user {
accountId
friends {
name
}
}
}This modular design is great for developer experience but leads to promise-heavy code. Each promise adds a minuscule, but non-zero amount of work for the event loop, which is discussed here.
To demonstrate, let’s say we want to write a feature that retrieves a user’s items on a shopping site. We might build a REST endpoint that looks like this:
/user/items/detailsThis would be powered by a few SQL queries.
SELECT item_id from users where user_id = $user_id;
SELECT details from items where id in (item_ids);A well-structured REST endpoint would have some relatively simple code that makes these database queries and massages the data back into a desired format. We would have no more than a few promises invoked and resolved in the request lifecycle.
In GraphQL, we would be encouraged to write a query like this:
user {
items {
id
details {
id
...otherFields
}
}
}If we have it well-structured as GraphQL resolvers, we might have type resolvers for users and item details.
resolvers: {
// returns { items: String[] }
User: async (req) => GetUserById(req.auth.user),
ItemDetails: async (req, { itemId }) => GetItemDetailsById(itemId),
}When executed, a GraphQL query with nested fields will result in a promise per field being created, such as:
const user = await getUser()
for itemId in user.items:
const { id, ...otherFields } = await GetItemDetailsById(itemId)If we use Dataloaders to prevent the N+1 query problem, this would translate to the same SQL queries as we described in the REST endpoint case. So the I/O cost would be as optimized as possible. But we would create one promise per item in a loop. And each promise adds work to the event loop.
I’ve written a benchmark of a GraphQL server that returns users to demonstrate the impact — the overhead increases as we increase the number of promises involved. We chose two GraphQL servers - Apollo Server + Express, and Mercurius.
The benchmarked queries return the same data - but one wraps every field response in a promise, and the other returns data synchronously. We return 100 items per user.

We see that wrapping each user and item in a promise causes a 2x or 3x increase in request latency.1
An invalid criticism here is that real-world GraphQL resolvers perform I/O, so the overhead here will reduce significantly as a percentage of the time taken by the resolver. A well-tuned database can perform two SQL queries to return 10k items in < 100 milliseconds, which is a reasonably small percentage of the high latency caused by the GraphQL server here (regardless of Express or Mercurius).
Real-world code is even messier - we might check feature flags or perform other ~async work in a resolver, which further increases the number of promises the event loop has to process.
Diagnosing the Problem
It’s useful to know how to diagnose this problem in certain operations. First, we should confirm that our application is actually blocked on the event loop. NodeJS exposes useful perf hooks to measure event loop utilization.
Next, we should confirm that our event loop isn’t blocked by code we control. In my case, I confirmed this by inspecting CPU profiles. If the event loop is occupied for >50ms with no obvious culprit in sight, the culprit is likely in the runtime.
Next, we can confirm how promise-heavy our code is through the following code snippet. Each GraphQL operation should increase the number of promises created and give us a clue about how promise-heavy our code is.
import async_hooks from 'async_hooks';
let count = 0;
const hook = async_hooks.createHook({
init(asyncId: number, type: string) {
if (type === 'PROMISE') {
count++;
}
},
});
hook.enable();
setInterval(() => {
console.log(`Promise count: ${count}`)
}, 1000);Another practical approach to determine whether the event loop is a blocker is determining the difference between client-reported database query latency, and database-reported query latency. For example, I noticed that client-side reporting of certain database queries was often >100 milliseconds, even though we were making an indexed query in a table with <1000 rows. As expected, we couldn’t replicate such a slow performance when manually querying our databases. This slow-down was because the event loop was overwhelmed after making database requests, so even though the database responded to certain requests very quickly, the web application did not get around to processing the response until after a significant delay.
Open-Source and Promises
Since async/await only affects request throughput in certain, promise-heavy conditions, most open-source code is not heavily optimized to prevent unnecessary promises. For example, GraphQL Shield, one of the most popular GraphQL authz libraries, assumes every field resolver is async. Therefore, it constructs a promise for every field in a GraphQL response, which further amplifies the number of promises created in the lifecycle of a request.
Typescript and JavaScript do not prevent developers from unnecessarily marking functions as `async`, so we need eslint rules like require-await to avoid unnecessary `await` calls on functions that do not construct promises.2
APM and Promises
Finally, we can incredibly slow down promise execution if we use Async Hooks, a deprecated but widely used NodeJS feature. Async hooks help us track asynchronous resources. For example, a tracing library might desire to track a request across callbacks and promises.
Unfortunately, any code we import may rely on this feature and can auto-enable it. For example, `dd-trace`, Datadog’s APM library (and likely many others), uses the feature to provide traces across promise executions.
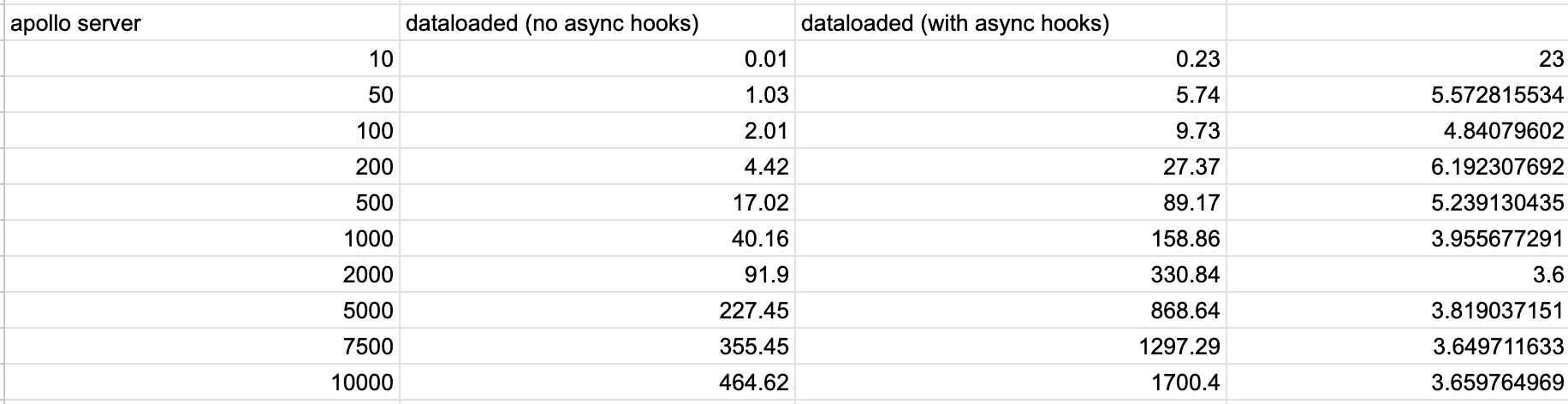
To understand the cost of async hooks, I added them to the GraphQL benchmark using Apollo Server. We run the same benchmark as above with AsyncLocalStorage (another slow, but supported feature), and with Async Hooks.


We see that Async Hooks adds a significant amount of latency to resolvers that return lists of data.


We roughly see that Async Hooks roughly adds a 3 - 3.5x overhead to these resolvers.
Datadog engineers are diligently working to reduce this overhead by contributing Node.JS and v8 features. However, improvements in this area are critical to get right and take time to be implemented.
Potential Solutions
In general, we want to reduce the overhead of promises and reduce the number of promises we invoke.
Reducing Promise Overhead
To reduce promise overhead, we want to minimize promise introspection features like Async Hooks in production.
Reducing the Number of Promises
To reduce promises invoked, we have a few areas to consider.
We could remove the use of GraphQL middleware, especially ones that assume every field is async.
We could also rewrite GraphQL queries to use fewer async type-resolvers by writing one-shot resolvers - a single resolver that manually queries the database and returns all the data needed for a performance-sensitive query, rather than relying on GraphQL to hydrate nested fields via type resolvers. Let’s take our earlier query:
user {
items {
id
details {
id
...otherFields
}
}
}We could write a one-shot resolver that implements the entire query:
const UserResolver = async (root, { userId }) => {
const [user, items] = await User.findById(userId);
const itemDetails = await ItemDetails.find({itemIds: items.map(i => i.id)});
return {
items: items.map(item => {
const details = itemDetails.find(d => d.id === item.id)
return {
id: item.id,
details: {
id: details.id,
...details
}
}
})
}
}Instead of multiple batches of promises, we fetch the user, items, and details in one shot. This brings up the meta-question about why use GraphQL in the first place, but that’s a larger conversation for a separate time.
I found a <5% difference between using dataloaders (that implicitly use promises) and using promises directly.
Interestingly, Meta is trying to solve a very similar issue in Python: https://engineering.fb.com/2023/10/05/developer-tools/python-312-meta-new-features/
But the last line in your post is the most interesting one :)
That's exactly the solution for this issue as I see it. You get all the benefits of a GraphQL schema where developers can pick and choose the data they need without having to use a set of very specific queries (probably also with the cost of overfetching as is the usual cost of using "generic" REST endpoints).
Once you DO know which queries are the important (and slow) ones, you add a very specific resolver for those and developers consuming the api will now be able to use that resolver for improved performance.
For the one-shot resolver solution, if the client doesn't request the items in the GraphQL query, you will still query them in the database even if you don't need them. So it may not be optimal for all use cases.